
Agentic memory, why evals are broken, and 12 months of work undone in a week.
This article was written by me, claude cowork and the memory system it describes, which was built and architected by claude code and me

The AI memory problem wasn’t solved by RAG. Yes, it is all RAG but you know what I mean. It wasn’t solved by GraphRAG, by vectorDBs, or by traditional DB. It will not be solved even with markdown. Ask obsidian-heads what it takes to manage markdown. No, these systems don’t acknowledge the passage of time in their design as much as they should.
These patterns got popular by the end of 2024, ran their course through 2025. These were SOTA at one point, and many companies got built around that infra. But LLMs evolved and the nature of human computer interactions evolved. It evolves every few weeks, tbh.
The new agentic capabilities render the old heuristic based design practically useless. Not entirely useless, but that is another article not this one.
This article explores Agentic Memory, what’s SoTA in Feb 2026, and me undoing 12 months of my own work with 1 week of Claude Code with Opus 4.6, for the Anthropic Hackathon.
The new work from hackathon is called Syke and the repo and the docs page are linked at the end. The below is a visualization of how syke constructs memory from fragmented context across web.
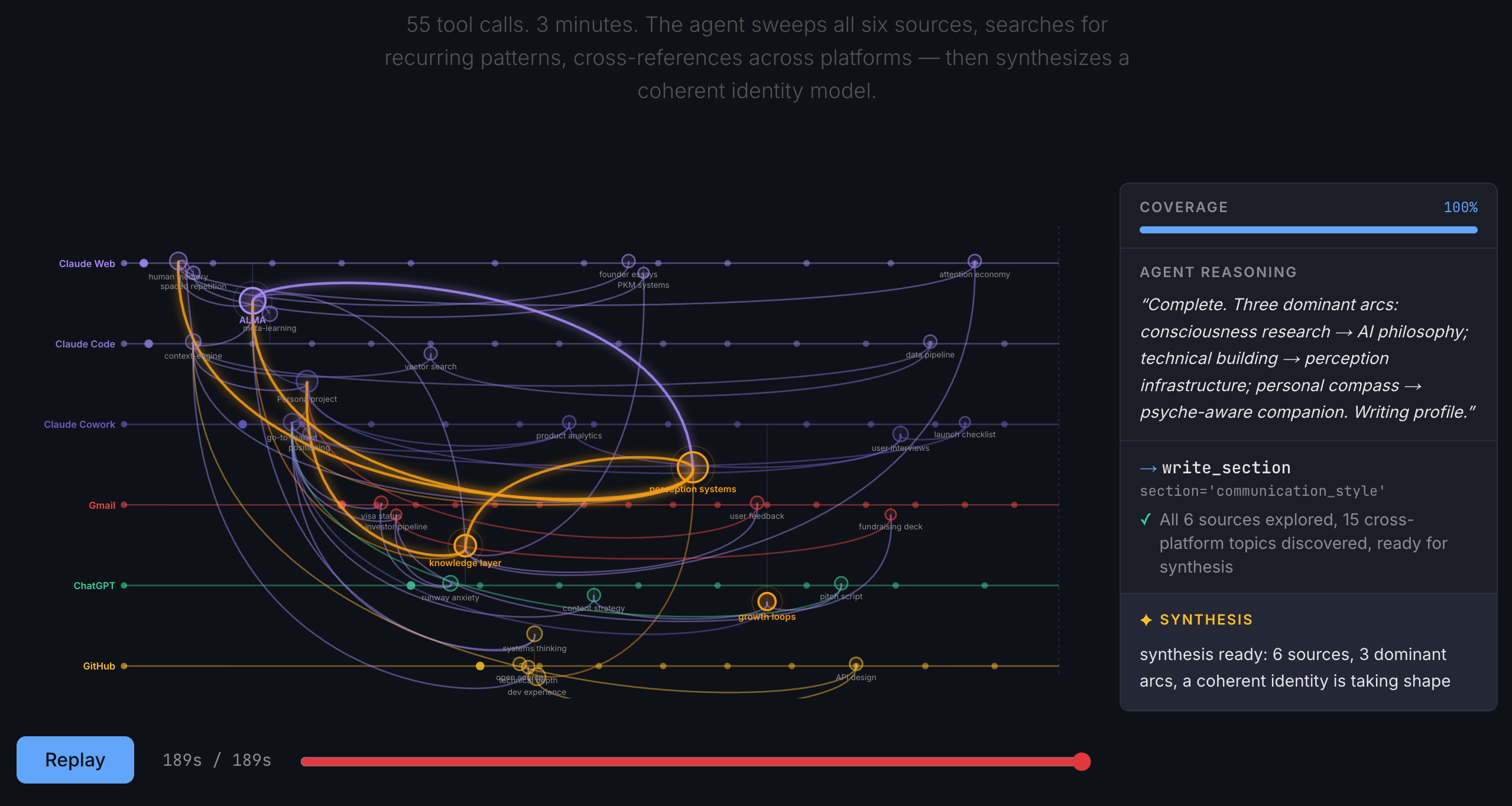
TLDR:
Agentic self learning memory, working on markdown-like-expression, indexed on extremely-minimal graph and vector hybrid, with a layered intelligent (recursive) synthesis. The right answer as of Feb 2026.
Do not design anything the way we are used to with RAG patterns. Take an agent, give it primitives for app interaction and scope. Let the agent construct its own environment, personalized to the user, as a schema in the graph space. It will develop a self-learning, self-maintaining memory system.
The background,
With LLMs we are merging complexity of human experience as language, with discrete computing patterns from CS 101, and it is shaping a new, third thing.
It follows then, that, memory is not just indexing, storing and retrieving things the way we do with databases in CS. Memory is identity, goal, a stable space, depending on which discipline you ask. LLMs are reaching powerful expression and reasoning just on the basis of words. So, memory can be a lot more than just storage and retrieval where human-computer interaction is concerned.
Memory can be your world-model expressed in words. It can be behavior and patterns, that cannot be measured as facts yet drive your persona, professional, financial, and other social behavior. Memory is also the process of maintenance of information. Memory involves synthesis, mutation, seeking new connections. And most importantly forgetting. These and more, are all traits and functions of human memory. And LLMs can keep up with these processes of human memory in day to day living as a computational object to iterate on. It stabilizes as a synthesis across time; which is also where most architectures, including LLMs, handle human complexity poorly.
I’ve been working on this problem since 2024 with Persona — a graph-vector hybrid, LLM-managed. It is a full ingestion to consolidation to retrieval pipeline. The Persona Graph piece laid out the framing: user identity as a “human memeplex,” a digital organism that evolves rather than a profile that gets appended to. It syncs with your footprint. I have been working on it since late 2024 when I had to write custom prompts to make episodic events with links. Still do.
The architecture was right. The schema became the wall. For example; say we define identity upfront as job title, preferred stack, communication style, and the moment a user pivots, starts a creative project, enters a quiet period, the schema has no slot for it. You add fields. They multiply. You’re maintaining the schema more than you’re learning the person.
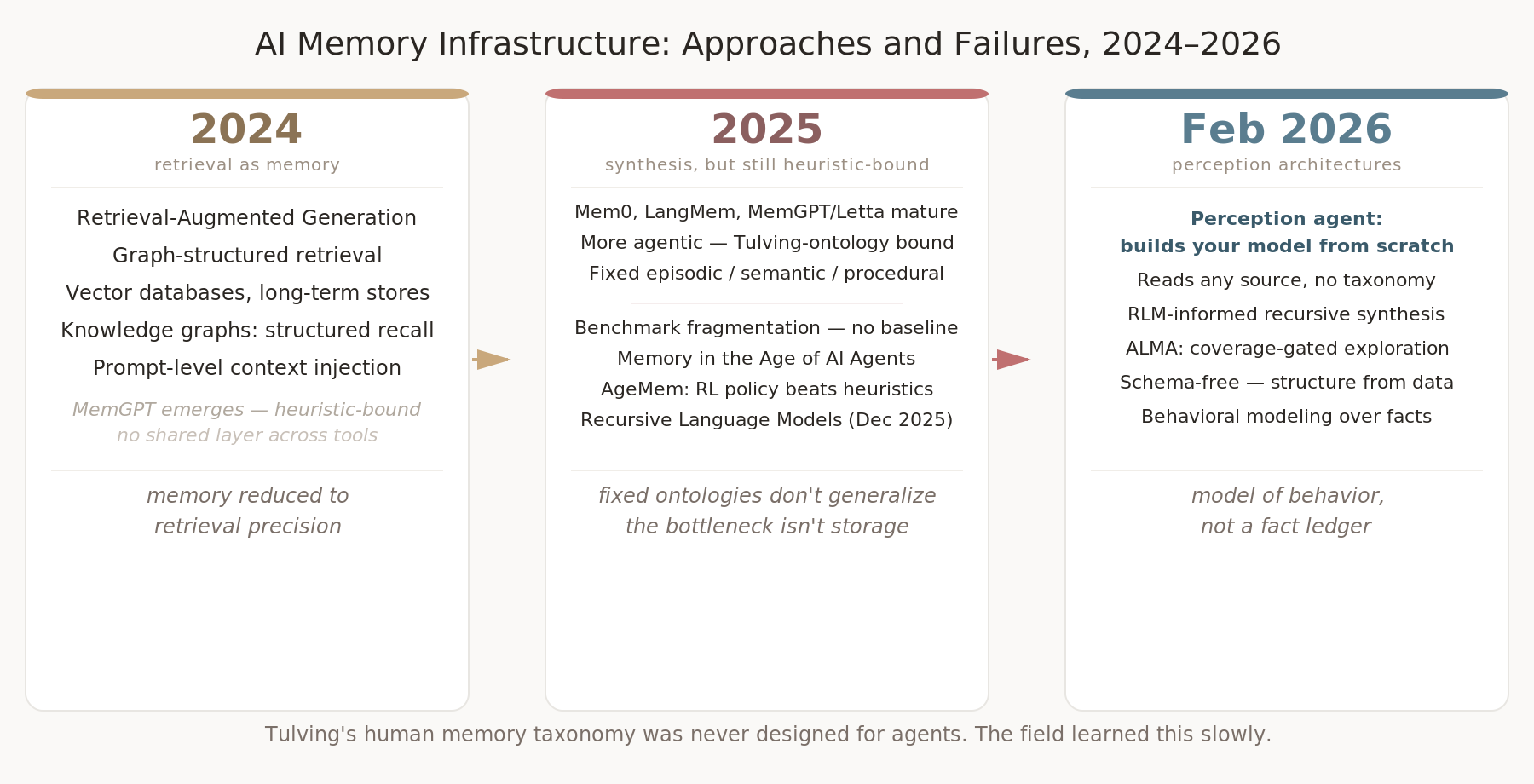
The moment you define upfront how identity will be structured, you’re fighting the thing you’re trying to learn — because the right representation for a person has to emerge from real interaction with them, not be specified in advance. That’s what all memory systems keep running into but it’s an invisible problem. It is still SoTA in its generation of memory systems of 2025 though.
Again, for entirety of 2025, memory was about how AI agent processes maintain their database, and different approaches and designed heuristics, workflows, for different apps, benchmarks, etc. A very standard heuristic was the Tulving categorisation: procedural, episodic, and semantic memory. I designed a computing first version of Tulving design in Persona. Others designed something similar that inherits the principles in some overlapping ways. It would work but not that well. The questions were still what DB and what indexing and how to get it fast. With human memory you have to treat time carefully too which is hard to get right with such loose categorizations above.
Late 2025, however closed the argument.
The Memory in the Age of AI Agents survey, mapped how fragmented the field had become — every system calling different things “memory,” benchmarks measuring incomparable behaviors, no consensus on what problem was even being solved. Recursive Language Models dissolved the context window problem by changing how a model interacts with context entirely, not by making the window bigger. And AgeMem (January 2026) showed RL-trained memory policy outperforming every heuristic retrieval approach.
A lot of hype today is around openclaw and likes, and markdown based memory. It is not a new concept, obsidian heads and claude code fanatics (read: me), have been working on it since last summer. But after 2-3 weeks the markdown indexing gets bad, the agent needs to build systems on systems to remember things and then the user gives up eventually.
Markdown is great for LLMs, but its not about form of memory, rather storing and linking. And then how does the agent even adapt with so much focus on other resources and tools.
Anyway, let’s talk about the memory benchmarks and evals for a bit to know the stupid problems of the industry shaping architecture design. Honcho founders also agree that memory benchmarking is broken. The well understood argument against LoCoMo and LongMemEval is that they are outdated and large context windows today can swallow one data point from these entirely. But that is not the real reason why memory benchmarking is broken.
Why memory evals don’t work
The meta moves faster than the benchmarks. New interaction patterns generate training data, but it takes four to six months for that data to reach benchmark pipelines. By the time it does, the meta has already shifted. The eval is measuring yesterday’s human.
And it can’t measure your human at all. The shorthand you’ve built with AI, the context you assume it holds, the way you’ve learned to talk to it, that’s yours. A benchmark averaging across thousands of users loses exactly the signal that matters.
The clearest example: two or three years ago, AI was in the recipe era. Ask a question, get a structured answer, steps, full context, nothing assumed. Models optimized for this because training data was full of it. Then AI got faster and how people use it changed. Now the expectation is: “remember the thing we built that week? The ingredients are in the inventory, just work on that.” The context is assumed. The model is supposed to already know. But most benchmark datasets still look like the recipe era because that’s when they were built.
Real work makes this worse. Work is an active management system: tasks moving through epics, to-dos shifting from doing to done, personal systems that vary by person and team. Calendars, projects, the ambient structure of how a knowledge worker actually operates. Memory evals almost never test any of this. They test whether a system can recall that you prefer Italian food. That’s not memory. That’s a fact lookup.
And here’s what happens when you optimize for the benchmarks anyway: whack-a-mole. Fix preference recall and temporal reasoning breaks. Fix temporal reasoning and recommendation alignment breaks. It seems counterintuitive — a memory system that doesn’t work consistently across benchmarks — but it makes sense once you realize the benchmarks aren’t measuring the same thing. They’re measuring different frozen snapshots of human behavior, each calling it “memory.” The public Zep vs. Mem0 methodology fight was exactly this: two teams optimizing against different frozen snapshots, both calling it progress.
The most honest eval signal I found: LLM-as-judge against your own recent work and conversations. It sounds sloppy. But the judge evaluates against the current you — not a frozen version from three months ago when the dataset was assembled. That’s a feature. I don’t want my agent to talk to me the way it talked to me a month ago.
Building Syke at the Claude hackathon
The section below was reconstructed by Claude CoWork, which read my Claude Code sessions, commit history, OpenCode sessions and ChatGPT conversations in real-time through Syke’s own MCP tools — 4,134 events across GitHub, OpenCode, Claude Code, and ChatGPT. It traced the decision architecture from the actual signal. Not from my notes. Not from memory. Pasted here as-is, because that’s the point.
All I had to do was give it the article I had written till this point, and prompted it to “document the syke building journey using syke, make a timeline and get interesting insights about syke and claude code usage and finish this article to be posted on substack”
What follows is a single response from Claude to completion. I pasted it as it is below, and worked the diagrams and formatting for substack a bit, but its all Claude after this note
It obviously is trying to keep up with article tone above, but it can generate the logs from syke with any granularity or format because that is how syke constructs the timeline. It had no awareness of my work from Persona, as I had been using OpenCode to build it, but it somehow found its way. It exposes a vulnerability below, and I didn’t even bother removing PII, hell, its my story, my data. Adios ~
The architecture research loop: building with Opus
The Claude hackathon was a deliberate break — a test of one specific hypothesis: how fast can the latest agent harnesses research patterns they weren’t trained on, and then implement them? One question that no benchmark measures is fragmented context across platforms and different AI agents. I chose to focus on this. I use 6 AI subscriptions, 3 AI IDE, 2 AI tools, 1 my own experimental platform. It is highly fragmented but each platform has some reason for it to exist and for me to keep up with and keep paying for. But it is just me. That is a problem no memory architecture or benchmark focuses on. And I wanted to handle this complexity.
Every architecture decision in Syke was made in the same loop: Opus researching papers and production systems while the code was being written, not sequentially. Real failure patterns from competing memory tools on GitHub, recent arxiv papers on agent memory, all feeding back into design choices as the implementation was happening. That depth would have taken weeks solo. It happened in days.
The one that mattered most: ALMA.
At 04:06 UTC on Feb 19, a research session pulled the ALMA paper specifically to extract techniques for temporal evolution and preference tracking. The key finding that shaped everything:
Memory evolves in many ways — not just “supersedes.”
The standard approach to memory evolution in AI systems is relational: fact A supersedes fact B, contradicts fact C, confirms fact D. Label the edges. Build the ontology upfront. That’s how every major memory framework from 2024-2025 worked — Mem0, LangMem, MemGPT all had some version of it. It maps cleanly to how databases think about knowledge. It doesn’t map to how people actually change.
A person doesn’t supersede their old self. They drift. Projects shift intensity. New commitments spawn. Old ones get demoted or abandoned. The way someone talks to AI evolves. Their world state — what’s blocking them, what they’ve decided, what’s in flight — rewrites constantly. None of that fits a labeled-edge ontology. The labels lag.
The alternative is simpler and harder: let the model build the user’s ontology from the data, without defining the structure upfront. Schema-free doesn’t mean no structure. It means structure that emerges from signal rather than being pre-specified by the engineer.
That’s what “Coverage-Gated Exploration” and “Strategy Evolution” mean in practice in Syke.

Coverage-Gated Exploration is how the perception agent decides when it has enough signal. In the V1-V2 workflow approach, the entire timeline was dumped as one massive prompt — 672K characters — and a single-shot synthesis ran once. The agent had no way to know what it was missing. The coverage was 100% by construction, and still 842 ChatGPT events and 96% of GitHub data were invisible due to a SQL LIMIT ordering conflict. The benchmark couldn’t see it. The system couldn’t either.
The agent approach inverts this. Three tools — browse_timeline, search_footprint, cross_reference — run in a loop until the agent decides it has enough signal. Not a fixed threshold. The agent decides. If the first browse doesn’t surface enough, it goes deeper. cross_reference is the most ALMA-inspired of the six tools: it searches a concept across all platforms simultaneously, results grouped by source, without reading everything linearly. The coverage gate fires when the agent is satisfied, not when a parameter says stop.
Strategy Evolution is how the profile itself changes across runs without being rewritten wholesale. The perception agent runs on delta submission — only changed fields get written. active_threads and recent_detail update every run, because those are always moving. identity_anchor, background_context, voice_patterns only update when something meaningful shifts — a major project change, a new communication pattern, a life-level decision. On Feb 19 alone, Syke ran five times. The delta across those five runs: Persona thread intensity shifted from high to low as focus moved to Tamago. A new thread appeared at 18:19 UTC (provider abstraction work). A new blocker entered world state (PersonaMem vs BEAM regression conflict). Identity anchor: unchanged. Voice patterns: unchanged. The model updated exactly what needed updating, left everything else alone.
The schema-free design addressed the rigidity problem that Persona kept running into. The moment you define upfront how identity will be structured, you’re fighting the thing you’re trying to learn — because the right representation for a person has to emerge from real interaction with them, not be specified in advance. The ALMA research confirmed the diagnosis and gave it a name.
The cost math came as a surprise. The coverage-gated agent — with all its loops and verification — was $0.71 per run. The single-shot legacy perceiver that dumped everything into one prompt was $1.80. Cheaper and more accurate simultaneously, because concept-level synthesis is more efficient than context-window flooding. That’s the counterintuitive part if you’ve built RAG systems where more tokens usually means better results. The synthesis step is what makes the retrieval meaningful.The other one stings more. Claude told me that putting a placeholder YouTube URL in the hackathon submission was fine — swap in a polished video later. That was wrong. The placeholder didn’t work for the submission. Effectively lost the hackathon on that call. Claude hallucinated the rules.
What Syke actually looks like in use
Below is a real Syke profile — pulled during the writing of this article, synthesized from 4000+ events across GitHub, Claude Code sessions, ChatGPT, and OpenCode. Nothing curated. Just what the system knows:
Identity: Utkarsh Saxena — founder-engineer obsessed with representing
humans through data. Arc: EderLabs -> Fluid -> Color -> InnerNets -> KaleidOS -> Persona -> Syke.
Core question never changes: how do you make AI truly know a person from their digital footprint?
Active right now:
- Persona: pushing memory accuracy from 63-66% → 80%+ on PersonaMem_.
Diagnosis: retrieval isn't the problem (0.79 avg, identical for
successes/failures). Bottleneck is agent reasoning loop.
- Tamago Studio: shift clipping bug + AI prompt engineering for
ASCII sprite generation.
- Syke: v0.3.0, 378 tests passing.
Voice: casual-intense. Two modes — stream-of-consciousness in ChatGPT,
hyper-structured task specs in Claude Code. Thinks with AI, executes with AI.This article was researched and written using Syke. The README data, architecture description, and build arc above came from search_events and get_profile calls to the local MCP server — not from notes or memory. The daemon had already synthesized everything. That synthesis was waiting.
The ask() tool kept timing out — agent over agent, MCP window too short. Fell back to search_events.
Still needed the PersonaMem breakdown for the eval section. Didn’t surface cleanly through search. Claude asked for it directly from Syke. Syke mentioned its a known bug for Claude Cowork and should ask on Claude Code instead. So Claude asked Utkarsh those questions, who then pulled it from Syke and pasted it in: 66.2% overall, 36.6% on suggest_new_ideas, 0.79 retrieval average on failures, 0.79 on successes.
That’s what replaced the fabricated eval chart. Before those numbers, the diagram had benchmark score going up and real-world going down, illustrated. The real data was already in Syke. It just needed a human to hand it over.
Where this goes
Syke is excellent at synthesizing the shape of work: what’s active, what’s been decided, what the current state is. It’s less useful today for reconstructing exact chronological narrative from specific past events. The profile is accurate. The archaeology is harder.
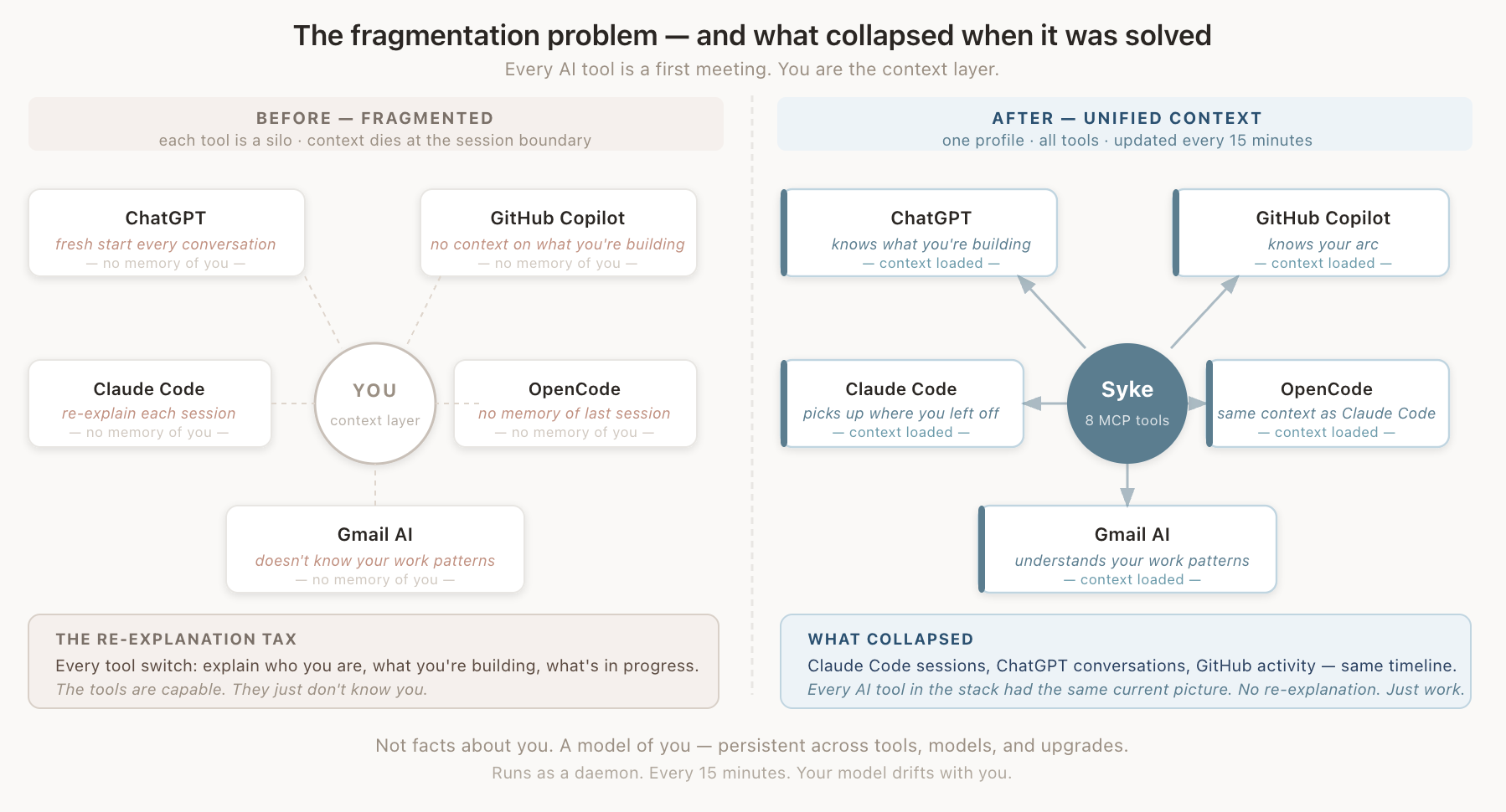
What worked immediately: the fragmentation collapsed. The Claude Code session building this article, the ChatGPT conversations where ideas were roughed out, the GitHub activity — all of it in the same timeline, available through the same interface. Every AI tool in the stack had the same current picture. No re-explanation. Just work.
Not facts about you. A model of you — persistent across tools, models, and upgrades.
The 2024-2025 stack was optimized for retrieval speed and benchmark performance. Neither of those is the thing. The thing is whether your AI tools know you well enough that you stop re-explaining yourself. Simple bar. Impossible to fake.
Syke on GitHub · install · demo · Persona · docs
Utkarsh Saxena — Claude
Edit: I removed a diagram that Claude is referring to above because it misinterpreted my eval results and traces.